
原文地址:The Architecture of Open Source Applications (aosabook.org) 作者:Bill Hoffman / Kenneth Martin
1999 年,美国国家医学图书馆聘请了一家名为 Kitware 的小公司来开发一种更好的方法来配置、构建和部署跨多个不同平台的复杂软件。这项工作是 Insight 分段和注册工具包 (ITK 1)的一部分。Kitware 是该项目的工程负责人,负责开发一个 ITK 研究人员和开发人员可以使用的构建系统。该系统必须易于使用,并允许研究人员最有效地利用编程时间。在这一指令下,CMake 应运而生,作为构建软件的陈旧 autoconf/libtool 方法的替代品。它旨在解决现有工具的弱点,同时保留其优势。
除了构建系统之外,多年来,CMake 已发展成为一个开发工具系列:CMake、CTest、CPack 和 CDash。CMake 是负责构建软件的构建工具。CTest 是一个测试驱动程序工具,用于运行回归测试。CPack 是一个打包工具,用于为使用 CMake 构建的软件创建特定于平台的安装程序。CDash 是一个用于显示测试结果和执行持续集成测试的 Web 应用程序。
CMake 的历史和开发目标
在开发 CMake 时,项目的正常做法是为 Unix 平台准备一个配置脚本和 Makefile,为 Windows 准备 Visual Studio 项目文件。这种构建系统的二元性使得许多项目的跨平台开发非常繁琐:向项目添加新源文件这一简单操作都很痛苦。开发人员的终极目标是拥有一个统一的构建系统。CMake 的开发人员对解决统一构建系统问题的两种方法都有经验。
一个经验是 1999 年的 VTK 构建系统。该系统由 Unix 的配置脚本和 Windows 的可执行文件组成pcmaker。pcmaker是一个 C 程序,它读取 Unix Makefile 并为 Windows 创建 NMake 文件。pcmaker的二进制可执行文件已提交到 VTK CVS 系统仓库。一些常见情况(例如添加新库)需要更改该源并提交新的二进制文件。虽然从某种意义上说这是一个统一的系统,但它有很多缺点。
开发人员的另一个经验是基于gmakeTargetJr 的构建系统。TargetJr 是一个最初在 Sun 工作站上开发的 C++ 计算机视觉环境。最初 TargetJr 使用imake系统创建 Makefile。然而,当某些时候需要移植到Windows 时,gmake系统就被创建了。基于gmake系统,Unix 编译器和 Windows 编译器都可以一起使用。在运行gmake前,系统需要设置几个环境变量。没有正确设置环境变量会导致系统运行失败,并且难以调试,尤其是对于最终用户而言。
这两个系统都存在一个严重的缺陷:它们迫使 Windows 开发人员使用命令行。经验丰富的 Windows 开发人员更喜欢使用集成开发环境 (IDE)。这会鼓励 Windows 开发人员手动创建 IDE 文件并将其贡献给项目,从而再次创建双重构建系统。除了缺乏 IDE 支持之外,上述两个系统都使得软件项目的合并变得极其困难。例如,VTK用于读取图像的模块非常少,主要是因为构建系统使用 libtiff 和 libjpeg 等库非常困难。
因此,大家决定为 ITK 和 C++ 开发一个新的构建系统,新构建系统的基本约束如下:
- 仅依赖于系统上安装的 C++ 编译器。
- 必须能够生成 Visual Studio IDE 输入文件。
- 必须易于创建基本的构建系统目标,包括静态库、共享库、可执行文件和插件。
- 必须能够运行构建时间代码生成器。
- 必须支持与源代码分离的构建。
- 必须能够执行系统自检,即能够自动确定目标系统能做什么和不能做什么。
- 必须自动对 C/C++ 头文件进行依赖性扫描。
- 所有功能都需要在所有受支持的平台上一致。
为了避免依赖任何额外的库和解析器,CMake 在设计时只有一个主要依赖项,即 C++ 编译器(如果要构建 C++ 代码,我们可以放心地假设它已经存在)。当时,在许多流行的 UNIX 和 Windows 系统上构建和安装 Tcl 等脚本语言都很困难。如今,在现代超级计算机和没有互联网连接的安全计算机上,这仍然是一个问题,因此构建第三方库仍然很困难。由于构建系统是软件包的基础,因此决定不向 CMake 引入任何额外的依赖项。这确实限制了 CMake 只能创建自己的简单语言,这种选择仍然导致一些人不喜欢 CMake。然而,当时最流行的嵌入式语言是 Tcl。如果 CMake 是一个基于 Tcl 的构建系统,它不太可能获得如今的流行度。
生成 IDE 项目文件的能力是 CMake 的一大卖点,但这样限制了 CMake 只能提供 IDE 可以原生支持的功能。不过,提供原生 IDE 构建文件的好处超过了限制。虽然这一决定使得 CMake 的开发更加困难,但它使得 ITK 和其他使用 CMake 的项目的开发变得容易得多。开发人员在使用他们最熟悉的工具时会更开心、更高效。通过允许开发人员使用他们喜欢的工具,项目可以充分利用他们最重要的资源:开发人员。
所有 C/C++ 程序都需要以下一个或多个基本软件构建块:可执行文件、静态库、共享库和插件。CMake 必须提供在所有受支持的平台上创建这些产品的能力。尽管所有平台都支持创建这些产品,但用于创建它们的编译器标志因编译器和平台而异。通过将复杂性和平台差异性隐藏在 CMake 简单命令后面,开发人员能够在 Windows、Unix 和 Mac 上创建它们。此功能使开发人员能够专注于项目,而不是如何构建共享库的细节。
代码生成器为构建系统增加了复杂性。从一开始,VTK 就提供了一个系统,通过解析 C++ 头文件并自动生成包装层,自动将 C++ 代码包装到 Tcl、Python 和 Java 中。这需要一个可以构建 C/C++ 可执行文件(包装器生成器)的构建系统,然后在构建时运行该可执行文件以创建更多 C/C++ 源代码(特定模块的包装器)。然后必须将生成的源代码编译成可执行文件或共享库,所有这些都必须在 IDE 环境和生成的 Makefile 中发生。
在开发灵活的跨平台 C/C++ 软件时,重要的是根据系统的特性进行编程,而不是针对特定系统。Autotools 有一个进行系统自检的模型,其中包括编译小段代码、检查和存储编译结果。由于 CMake 旨在实现跨平台,因此它采用了类似的系统自检技术。这允许开发人员针对规范系统而不是特定系统进行编程。这对于实现未来的可移植性非常重要,因为编译器和操作系统会随着时间而变化。例如,像这样的代码:
| |
比这样的代码更脆弱:
| |
CMake 的另一个早期需求也来自 autotools:能够创建与源代码树分开的构建树。这允许在同一源代码树上执行多种构建类型。它还可以防止源代码树被构建文件弄得乱七八糟,这通常会使版本控制系统感到困惑。
构建系统最重要的功能之一是管理依赖项的能力。如果更改了源文件,则必须重建使用该源文件的所有产品。对于 C/C++ 代码,作为依赖项的一部分还必须检查.c或.cpp文件所包含的头文件。由于依赖项信息不正确,导致部分修改的代码没有被编译,这类问题追踪起来非常耗时。
新构建系统的所有要求和功能都必须在所有支持的平台上同样出色地运行。CMake 需要为开发人员提供一个简单的 API,以便他们创建复杂的软件系统,而无需了解平台细节。实际上,使用 CMake 构建的软件将复杂问题外包给了 CMake 团队。一旦构建工具的愿景和基本要求得以形成,就需要以敏捷的方式进行实施。ITK 几乎从第一天起就需要一个构建系统。CMake 的第一个版本并未满足愿景中规定的所有要求,但它们能够在 Windows 和 Unix 上构建。
CMake 是如何实现的
如上所述,CMake 的开发语言是 C 和 C++。为了解释其内部原理,本节将首先从用户的角度描述 CMake 流程,然后检查其结构。
CMake 处理流程
CMake 有两个主要阶段。第一个阶段是“配置”步骤,CMake 处理所有输入并创建要执行的构建的中间文件。下一个阶段是“生成”步骤。在此阶段,将创建实际的构建文件。
环境变量
在 1999 年甚至现在的许多构建系统中,在构建项目期间都会使用 shell 级环境变量。项目通常有一个 PROJECT_ROOT 环境变量,它指向源树的根位置。环境变量还用于指向可选或外部包。这种方法的问题在于,为了使构建工作正常,每次执行构建时都需要设置所有这些外部变量。为了解决这个问题,CMake 有一个缓存文件,它将构建所需的所有变量存储在一个地方。这些变量不是 shell 或环境变量,而是 CMake 变量。第一次为特定构建树运行 CMake 时,它会创建一个CMakeCache.txt文件,其中存储了该构建的所有持久变量。由于该文件是构建树的一部分,因此在每次运行期间,这些变量始终可供 CMake 使用。
配置步骤
在配置步骤中,如果存在CMakeCache.txt,CMake 首先读取CMakeCache.txt。然后,在给定 CMake 源码树的根目录中的读取CMakeLists.txt 。在配置步骤中,CMakeLists.txt文件由 CMake 语言解析器解析,在该文件中的每个 CMake 命令都由命令解析器执行。在此步骤中,使用include和add_subdirectory包含的其他CMakeLists.txt也可以被 CMake 命令解析。CMake 对每个可以在 CMake 语言中使用的命令都有一个 C++ 对象,比如add_library,if,add_executable 和 add_subdirectory 和 include。实际上,整个 CMake 语言都是作为对命令的调用实现的,解析器只是将 CMake 输入文件转换为命令调用和作为命令参数的字符串列表。
配置步骤本质上是“运行”用户提供的 CMake 代码。执行完所有代码并计算完所有缓存变量值后,CMake 将在内存中临时保存要构建的项目。这将包括所有库、可执行文件、自定义命令以及为所选生成器创建最终构建文件所需的所有其他信息。此时,该CMakeCache.txt文件将保存到磁盘以供将来运行 CMake 时使用。
项目的在内存里是目标的集合,这些目标是将要构建的内容,例如库和可执行文件。CMake 还支持自定义目标:用户可以定义其输入和输出,并提供要在构建时运行的自定义可执行文件或脚本。CMake 将每个目标存储在一个cmTarget对象中,这些对象依次存储在cmMakefile对象中,该对象是源码树给定目录中找到的所有目标的存储位置,最终结果是包含cmTarget对象映射的对象cmMakefile树。
生成步骤
一旦完成配置步骤,就可以进行生成步骤。生成步骤是 CMake 为用户选择的目标构建工具创建构建文件的步骤。此时,目标(库、可执行文件、自定义目标)的内部表示将转换为 IDE 构建工具(如 Visual Studio)的输入,或一组由make执行的 Makefile。配置步骤后的 CMake 的内部表示尽可能通用,以便尽可能多的代码和数据结构可以在不同的构建工具之间共享。
该过程的概览如图 1所示:
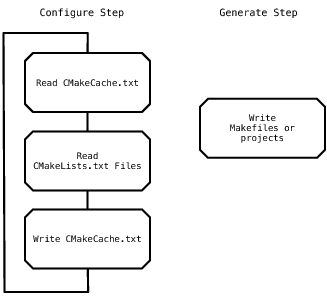 图 1 Cmake 流程概述
图 1 Cmake 流程概述
CMake 实现
CMake 对象
CMake 是一个使用继承、设计模式和封装的面向对象语言,主要的 C++ 对象及其关系如图2所示:
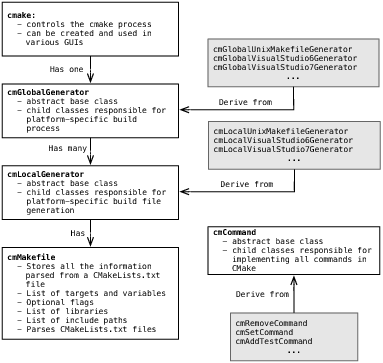 图 2 CMake对象
图 2 CMake对象
解析每个CMakeLists.txt文件的结果都存储在cmMakefile对象中。除了存储有关目录的信息之外,cmMakefile还控制CMakeLists.txt文件的解析,解析函数基于 lex/yacc 来解析 CMake 语言。由于 CMake 语言语法很少更改,并且 lex 和 yacc 并不总是在构建 CMake 的系统上可用,因此 lex 和 yacc 输出文件会处理并存储到Source目录,并与其他手写文件一起受到版本控制。
CMake 中另一个重要的类是cmCommand。这是 CMake 语言中所有命令实现的基类。每个子类不仅提供命令的实现,还需要提供其文档。例如,请参阅类上的文档方法cmUnsetCommand:
| |
依赖关系分析
CMake 内置具有针对单个 Fortran、C 和 C++ 源代码文件的强大依赖关系分析功能。由于集成开发环境 (IDE) 支持并维护文件依赖关系信息,因此 CMake 在这些构建系统会跳过依赖关系分析步骤。对于 IDE 构建,CMake 会创建一个 IDE 输入文件,并让 IDE 处理文件级依赖关系信息。目标级依赖关系信息会被转换为 IDE 格式的特殊依赖关系信息。
对于基于 Makefile 的构建,原生 make 程序不知道如何自动计算并保持最新依赖信息。对于这些构建,CMake 会自动计算 C、C++ 和 Fortran 文件的依赖信息,这些依赖的生成和维护均由 CMake 自动完成。一旦项目由 CMake 进行配置,用户只需运行make,CMake 会完成其余工作。
虽然用户不需要知道 CMake 如何工作,但查看项目的依赖信息文件还是很有用的。每个目标的这些信息存储在四个文件中,分别为depend.make、flags.make、build.make和DependInfo.cmake。depend.make存储目录中所有目标文件的依赖信息。flags.make包含用于此目标源文件的编译标志。如果它们发生变化,那么将重新编译文件。DependInfo.cmake用于使依赖信息保持最新,并包含有关哪些文件属于项目的一部分以及它们使用哪种语言的信息。最后,构建依赖项的规则存储在build.make中。如果目标的依赖项已过期,则将重新计算该目标的依赖信息,从而使依赖信息保持最新。这样做是因为对 .h 文件的更改可能会添加新的依赖项。
CTest 和 CPack
在此过程中,CMake 从一个构建系统发展成为一套用于构建、测试和打包软件的工具。除了命令行cmake和 CMake GUI 程序外,CMake 还附带测试工具 CTest 和打包工具 CPack。CTest 和 CPack 与 CMake 共享相同的代码库,但它们不是基础构建所必需的独立工具。
可执行ctest文件用于运行回归测试。项目可以使用add_test命令轻松创建供 CTest 运行的测试程序。测试程序可以基于 CTest 运行,它还可用于将测试结果发送到 CDash 应用程序以供在 Web 上查看。CTest 和 CDash 总体上类似于 Hudson 测试工具,但是它们有一个很大的区别:CTest 旨在允许更加分布式的测试环境。可以设置客户端从版本控制系统中获取取源代码、运行测试并将结果发送到 CDash。使用 Hudson,客户端计算机必须授予 Hudson 对计算机的 ssh 访问权限,以便可以运行测试。
cpack工具用于为项目创建安装程序,CPack 的工作方式与 CMake 的构建部分非常相似:它与其他打包工具交互。例如,在 Windows 上,NSIS 打包工具用于从项目创建可执行安装程序,CPack 运行项目的安装规则来创建安装树,然后将其提供给 NSIS 等安装程序。CPack 还支持创建 RPM、Debian.deb文件.tar,.tar.gz和自解压 tar 文件。
图形界面
许多用户第一次看到 CMake 的地方就是 CMake 的用户界面程序之一。CMake 有两个主要的用户界面程序:一个基于 Qt 的窗口应用程序和一个基于curses命令行的图形应用程序。这些 GUI 是CMakeCache.txt文件的图形编辑器。它们是相对简单的界面,有两个按钮,配置和生成,用于触发 CMake 过程的主要阶段。基于 curses 的 GUI 可在 Unix TTY 类型的平台和 Cygwin 上使用。Qt GUI 可在所有平台上使用。GUI 可以在图 3和图 4中看到。
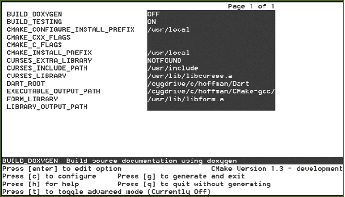 图 3 命令行界面
图 3 命令行界面
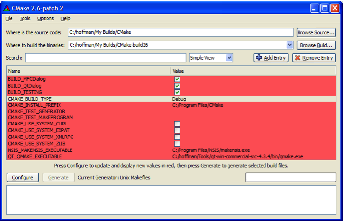 图 4 基于图形的界面
图 4 基于图形的界面
两个 GUI 的左侧都有缓存变量名称,右侧有值。用户可以将右侧的值更改为适合构建的值。变量有两种类型:普通变量和高级变量。默认情况下,普通变量会显示给用户。项目可以确定CMakeLists.txt项目文件中的哪些变量是高级变量。这允许用户在构建过程中获得尽可能少的选项。
由于缓存值可以在执行命令时修改,因此最终构建过程可以是迭代的。例如,打开一个选项可能会显示其他选项。出于这个原因,GUI 会禁用“生成”按钮,直到用户有机会至少查看一次所有选项。每次按下配置按钮时,尚未呈现给用户的新缓存变量都会以红色显示。一旦在配置运行期间没有创建新的缓存变量,就会启用生成按钮。
测试 CMake
任何新的 CMake 开发人员都会首先了解 CMake 开发中使用的测试流程。该流程利用了 CMake 系列工具(CMake、CTest、CPack 和 CDash)。当代码代码完成修改并提交到版本控制系统时,持续集成测试机器会自动使用 CTest 构建和测试新的 CMake 代码。结果将发送到 CDash 服务器,如果有任何构建错误、编译器警告或测试失败,服务器会通过电子邮件通知开发人员。
该过程是典型的持续集成测试系统,当新代码被提交到 CMake 仓库时,它会在支持 CMake 的平台上自动进行测试。鉴于 CMake 支持的编译器和平台数量众多,这种类型的测试系统对于开发稳定的构建系统至关重要。
例如,如果新开发人员想要添加对新平台的支持,那么他或她被问到的第一个问题是他们是否可以为该系统提供夜间仪表板客户端。如果没有持续的测试,新系统在一段时间后不可避免地会停止工作。
经验教训
CMake 从第一天起就成功地构建了 ITK,这是该项目最重要的部分。如果我们可以重新开发 CMake,不会有太大的变化。然而,总有可以做得更好的地方。
向后兼容性
保持向后兼容性对 CMake 开发团队来说非常重要。该项目的主要目标是使软件构建更加容易。当项目或开发人员选择 CMake 作为构建工具时,重要的是要尊重这一选择,并尽量避免在 CMake 的未来版本中破坏该构建。CMake 2.6 实施了一个策略系统,其中对 CMake 的更改会破坏现有行为,但会发出警告,但仍会执行旧行为。每个CMakeLists.txt文件都需要指定它们期望使用哪个版本的 CMake。较新版本的 CMake 可能会发出警告,但仍会像旧版本一样构建项目。
语言,语言,语言
CMake 语言本意是非常简单。然而,当一个新项目考虑使用 CMake 时,这是采用该语言的主要障碍之一。鉴于其用户快速增长,CMake 语言确实有一些怪癖。该语言的第一个解析器甚至不是基于 lex/yacc 的,而只是一个简单的字符串解析器。如果有机会重新设计该语言,我们会花一些时间寻找一种已经存在的好用的嵌入式语言。Lua 可能是最合适的选择。它非常小巧简洁。即使不使用像 Lua 这样的外部语言,我也会从一开始就更多地考虑现有的语言。
插件不起作用
为了使项目能够扩展 CMake 语言,CMake 有一个插件类。这允许项目用 C 语言创建新的 CMake 命令。这在当时听起来是个好主意,并且为 C 定义了接口,以便可以使用不同的编译器。然而,随着 32/64 位 Windows 和 Linux 等多种 API 系统的出现,插件的兼容性变得难以维护。虽然使用 CMake 语言扩展 CMake 并不那么强大,但它可以避免 CMake 崩溃或无法构建项目,因为插件无法构建或加载。
减少暴露的 API
在 CMake 项目开发过程中,我们学到的一大教训是,您不必维护与用户无法访问的内容的向后兼容性。在 CMake 开发过程中,用户和客户曾多次要求将 CMake 制作成一个库,以便其他语言可以绑定到 CMake 功能。这不仅会分裂 CMake 用户社区,使其拥有多种使用 CMake 的不同方式,而且会给 CMake 项目带来巨大的维护成本。
脚注
http://www.itk.org/